Grove: Distributed ML Training Over AirDrop
I wanted to train a model across every MacBook in a room without any setup. Every distributed training tool I looked at required knowing the addresses of other machines upfront, and none of them worked on restricted networks like eduroam. It seemed like devices sitting next to each other shouldn't need any configuration to communicate.
grove start train.py -n 4 # on one Mac
grove join # on the others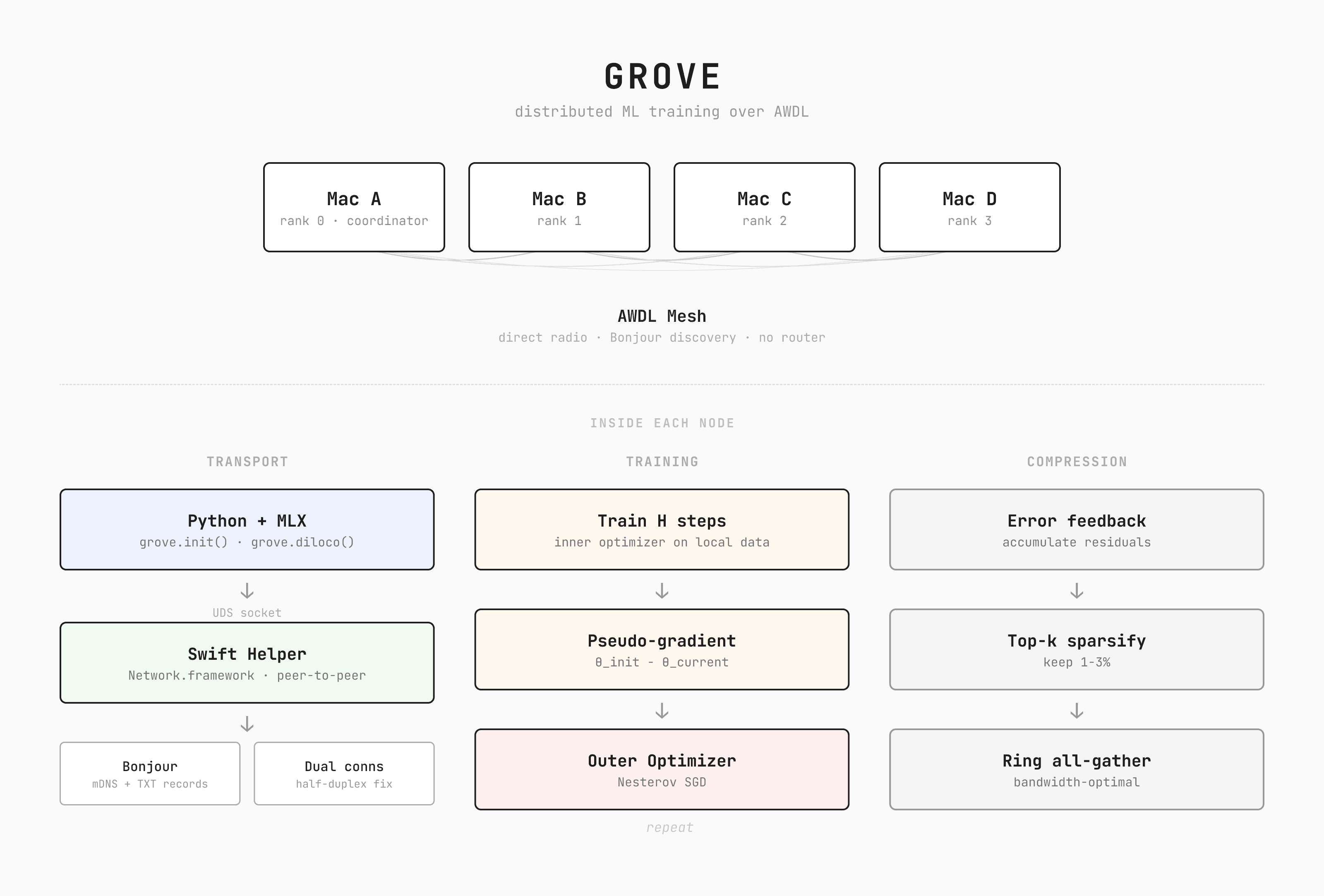
Going beneath the network
The insight that changed the direction of the project was realizing that Apple devices already know how to communicate without a network. AirDrop works without being connected to any WiFi network. It works on restricted university WiFi. It works between strangers on a train. The protocol responsible is AWDL (Apple Wireless Direct Link), Apple's proprietary alternative to WiFi Direct. It's built on the same WiFi standard your laptop already uses, but operates independently from any WiFi network you're connected to.
When Apple devices are nearby, their WiFi chips periodically tune to a dedicated channel and exchange data in brief synchronized time windows, then switch back to the regular WiFi channel. No router is involved. This time-sharing means AWDL gets a fraction of the radio's total bandwidth. When devices share a WiFi network, a direct connection over that network is significantly faster. But not all networks allow it. University networks like eduroam use client isolation, where the access point drops all traffic between wireless devices. Two laptops on eduroam can both reach the internet but can't reach each other.
Grove uses both paths. Discovery always runs over AWDL, which works regardless of network restrictions. After devices find each other, grove probes for a direct WiFi connection. If it works, data transfers upgrade transparently. If it doesn't, everything stays on AWDL. The closest thing in the space is EXO Labs, which does distributed inference across Apple devices using standard networking and RDMA over Thunderbolt. Grove takes a different approach for a different problem, training rather than inference, and AWDL rather than standard networking, so that it works even when there's no network available at all.
AWDL is locked behind Apple's Network.framework with a specific flag (includePeerToPeer = true), and Python has no way to access it. Rather than rewrite everything in Swift, I built a minimal Swift sidecar that grove compiles on first run. Python handles the ML, Swift handles the radio, and they communicate through a local IPC channel (Unix domain socket). From the user's perspective the library is pure Python. Under the hood there's a compiled Swift binary managing the AWDL connections.
Discovery and connection
Joining a cluster happens in two phases. First, the Swift helper runs in discover mode, using Bonjour to scan for coordinators advertising _grove._tcp services. The coordinator's TXT record contains the cluster name, expected node count, and script name. Available clusters show up in a terminal picker that updates in real time. Once you select one, the helper restarts in mesh mode and establishes full peer-to-peer connections with every other node.
The two-phase split is a UX decision. Discovery is lightweight and can run continuously, updating the picker in real time as clusters appear and disappear. Mesh mode is heavier, establishing full connections to every peer. Keeping them separate means the browsing experience stays responsive and the connection setup only happens once you've committed to a cluster.
Ranks are assigned by sorting Bonjour service names, which are prefixed with the rank, so the coordinator is always rank 0 without any negotiation. The coordinator also transfers the training script to workers over the same connection, so joining nodes don't need a copy of the code.
In practice, I only got reliable one-way flow per NWConnection. It took some time to figure out why bidirectional transfers were silently failing when I tried to treat a single connection like a normal full-duplex socket. I didn't have a second Mac at the time, so I built an iOS test app that acted as a grove peer and used my iPhone to debug the transfer protocol. Each peer pair now opens two connections, one per direction, which also lets you pipeline send and receive simultaneously.
You can test the full AWDL code path on a single machine. Bonjour discovery goes through mDNSResponder, a system daemon that sees all advertised services regardless of which process registered them. Two grove processes on the same Mac discover each other through the same code path that would run across separate machines, with the kernel routing packets locally instead of over the radio.
Each connection carries both tensor data and control plane messages (heartbeats, membership updates, script transfer), demultiplexed by a 4-byte magic prefix. GROV marks tensor data, GCTL marks control messages. AWDL delivers data in unpredictable chunk sizes, so a frame reader on the Swift side buffers incoming bytes and drains complete length-prefixed messages as they arrive.
The bandwidth determines the algorithm
Once the transport layer worked, the question became what to actually send over it. Tensor parallelism splits individual weight matrices across devices, requiring communication within every layer. Pipeline parallelism splits layers sequentially across devices, requiring activation transfers between stages. Both need high-bandwidth, low-latency interconnects. Over a wireless link, neither is viable.
Data parallelism is the only approach that makes sense here. Each device holds a full copy of the model, trains on its own data, and periodically averages gradients with everyone else. The communication pattern is a single sync step rather than continuous back-and-forth. But even this is expensive over wireless. Syncing hundreds of megabytes of gradients for even a small model takes on the order of a minute over AWDL. The GPU would spend more time waiting for the network than actually training.
This constraint ended up being one of the more interesting parts of the project. The speed of your link doesn't just affect how fast you train. It determines what optimization algorithm you can use at all.
DiLoCo (Douillard et al., 2023) was designed for exactly this regime. Instead of syncing every step, each device trains independently for steps, then computes a pseudo-gradient, the difference between where parameters started and where they ended up:
These are averaged across workers and used to update the global parameters with momentum:
The outer optimizer is SGD with Nesterov momentum ( in the original paper). With , you communicate once every 500 steps instead of every step.
SparseLoCo (Sarfi et al., 2025) goes further by compressing the pseudo-gradient before transmission. Instead of sending every value, each worker maintains an error buffer that accumulates pseudo-gradients over time. Each sync round, only the largest 1-3% of values in the buffer are transmitted. After sending, those values reset to zero, giving smaller values a chance to rise to the top in subsequent rounds.
Values that miss one round aren't discarded. They stay in the error buffer, with decay, and keep accumulating until they become important enough to send. This carry-forward also acts as a form of momentum, which is why SparseLoCo can use a simpler outer optimizer than DiLoCo and still converge. At our defaults this gives roughly 32x payload compression.
I also implemented DeMo (Peng et al., 2024), which takes a different approach. It syncs every step, but transforms gradients into frequency space via DCT and sends only the most significant components, so the per-step payload is small. Better suited for fast local networks than wireless.
The pattern across all three is the same. The slower your link, the more you need to decouple computation from communication. What you can send is bounded by what the link can carry.
Making it fast
The gradient sync passes data around the devices in a ring, which is the most efficient topology for averaging across N machines. A subtle issue with rings is that every node needs to send and receive simultaneously. If all nodes try to send first, nobody is receiving, sockets fill up, and the system deadlocks. Each send runs in a background thread so the main thread can immediately start receiving from the other direction.
Early on, pushing a full gradient buffer through a single send call crashed with ENOBUFS. The instinct was to tune socket buffer sizes or add backoff and retry, but the actual fix was to split the ring into 1M-element slices at the algorithm level so each individual message fits comfortably within the kernel buffer budget. Same total data transferred, but smaller messages stopped tripping the buffer limits I was hitting on macOS.
The coordinator participates in training as rank 0 rather than being a separate orchestration process. This means the person who starts the cluster also contributes compute. The coordinator runs heartbeat monitoring, straggler detection, and ring reformation on background threads alongside its own training loop. If a node drops out, the remaining nodes re-form the ring and continue training without it.
The base SparseLoCo loop is synchronous at each sync point, meaning the GPU would normally idle while gradients are in transit. In Grove, I overlap communication with computation using the approach from Streaming DiLoCo (Douillard et al., 2025). The top-k compression and sparse encoding run on the Metal GPU via MLX, and a background thread sends the result through the ring while the GPU starts the next batch of training steps. When the delayed result arrives, it's blended 50/50 with the current local parameters, preserving both local progress and the global update. The staleness is bounded at one round, and if the sync takes longer than the next H steps, the main thread just waits, so the async path can only help, never hurt.
Both DiLoCo and SparseLoCo keep a snapshot of the starting parameters and additional optimizer state, so the memory overhead is about 3x the trainable parameter size. For full fine-tuning of a large model this matters, but the expected use case is LoRA, where only about 1% of parameters are trainable. 3x of 1% is negligible.
Closing thoughts
The interesting problems in distributed training turned out not to be the algorithms. The core of DiLoCo and SparseLoCo are each under 200 lines. The interesting problems live at the systems boundary, in places like getting processes to discover each other on a network designed to prevent exactly that, or bridging a language boundary between Python and Swift through an IPC socket, or discovering that AWDL silently violates assumptions every other transport layer respects.
Grove is early and rough around the edges, but the core loop works. I think there's a lot more to build on top of what Apple Silicon already gives you that not many people have explored yet.